Narrative Graph Models
When I decided to rewrite the Muturangi manuscript as an interactive fiction app, there were various core design problems which seemed like they’d be quite frustrating to solve without a general purpose graph representation of the story and world data:
- Each passage of linear text in the story should be associated with viewpoint character and a timepoint in the storyline
- Each passage should have one or more choices that allow the reader to follow a path to the next passage in the story
- Emails, messages and web pages sent to and from each character should be associated (or queryable) at each timepoint from the perspective of each viewpoint character
- In order to write a parody of surveillence technology, it should be possible to introspect the network of emails and messages for each character at each timepoint
- It should be possible to add additional arbitrary layers of metadata to the world without needing to change any existing data or modify existing schemas
- The reader’s path through the story should be traceable and treated as a single data object in its own right
Hence my initial thoughts that ideas based on graph computing seemed like a powerful way to unify these different aspects of the story and structure the data in a way that made its inherent chaos and complexity more manageable.
Unfortunately for my sanity, putting all this into practice hasn’t been quite as straightforward as I had hoped.
These are my notes on various different narrative graph models and some of the consequences and tradeoffs involved. They’re early thoughts; experimental rather than definitive. There are many subtleties that I don’t feel I’ve got an adequate grasp of yet. I’ll keep this page updated as I dig deeper and learn more.
Graph Structures
Depending on which way you look at things, a graph is an abstract mathematical concept and/or a type of data structure with a particular combination of features:
- A collection of nodes each of which is a uniquely identifiable object.
- Zero or more edges each of which connect two nodes together.
The concept is much easier to explain visually:
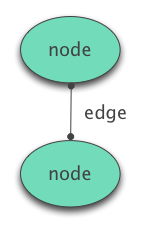
From this simple foundation, a huge variety of different constraints, structures and special cases emerge:
- Graphs can be directed where the edges point in a single fixed direction (arrows):
- Graphs can be undirected where the edges can be traversed in either direction.
- Graphs can have cycles where subsets of edges connect the same nodes in a loop.
- Trees are graphs without cycles with no more than one path connecting any two nodes.
- Property graphs embed a meta model of key-value properties into the nodes and edges.
Graph Technologies
There’s a wide variety of Databases, frameworks and libraries that support reading and writing data in a graph-based form. These range from transactional and persistent databases like Neo4j and Titan, graph-oriented document databases like OrientDB, all the way down to data structure toolkits and native Set and Vector types in various programming languages.
These are notes about architecture and modeling patterns though, and I’m trying to be as broad and general as I can be, so I won’t go into too much detail about specific technologies.
Graphs in Fiction
In computing, graphs are widely understood to be extremely powerful when modeling real world scenarios or reifying social network data, but they’re not often used explicitly to model the domain of fictional universes and interactive storytelling.
The most prominent example of using graphs in the context of fiction is the Marvel Entertainment database which maps out the complex and contradictory 70 year history of Marvel Universe characters and creative assets to an extraordinary fine-grained level of detail.
Narrative Graphs
What is a narrative graph exactly? As a foundation for the patterns I’m describing here, a basic definition would be:
- A model for defining a narrative text as a network of nodes and relationships.
- Each node in the graph represents a discrete unit of the story (chapter, scene, passage, paragraph, etc).
- Narrative sequences (consequences of actions, choices, or the passage of time) are created by drawing edges between the different nodes in the story.
Organising a narrative with this structure leads to some interesting consequences:
- Different paths through the story can be represented through graph traversals.
- The state at a particular point in the story can be computed based on the path taken to get there.
- The same data model can be used to generate variations of a book and an interactive interface.
Narrative graphs can be used to implement both choice fiction and world models although there are different affordances in either case. In this context, I’m mostly concerned with narratives involving linear choices, since this is the basis for the creative work I’m currently doing.
Implicit & Explicit Models
Narrative graph models can be classified as implicit or explicit, depending on whether or not the graph data structure is a primary representation of the story or simply a consequence of how the story is put together.
Because graphs are such a universal data structure and so broad in their potential scope, any text could understood as a graph on some level, even when it has been put together with quite a different set of tools and techniques. So I guess there’s the question of why focus on explicit graph modeling at all?
One of the primary reasons why I’m exploring this is that I’m deeply interested in how the process of creativity is shaped and directed by the particular system used for writing. This is true of any interactive fiction system.
As the primary representation for modeling stories, a graph-oriented approach leads to some intriguing possibilities for implementing choice fiction in a much more concise and declarative way than traditional imperative programming models and relational databases can achieve.
Branching Patterns
Sam Kabo Ashwell’s brilliant definition of the Standard Patterns in Choice-Based Games is the primary reference I’m working from here. Note that most of these branching patterns refer to directed graphs where the choices at each point in the story flow in linear order and backtracking isn’t allowed.
Tracking State
Tracking state involves storing variables that represent quantitative aspects of the story. For example, many old school gamebooks included dice rolling mechanics borrowed from Dungeons & Dragons style role playing games.
But state tracking can go beyond things like hit points and inventory. State can also be used to represent social information that has the potential to affect the narrative like affinity towards certain characters, honesty/dishonesty, rudeness/politeness indicators and so forth.
For authors interested in the dramatic and creative possibilities of tracking state, the primary problem is the tension between adapting dynamically to reader choices and a combinatorial explosion of different story branches (the cause of considerable headaches). I’m specifically leaving these concerns out of the implementation patterns described here.
When a story is modeled explicitly as a narrative graph, it’s possible to track state in a more functional way that avoids the need to update global variables in various different places. If the adjustments to state are stored as immutable properties on nodes or edges, the ‘current state’ can be computed based on graph traversals that collect or sum these properties along the path taken to reach the current node. This is extremely well suited to surfacing stories over HTTP.
Hypertext Networks
Hypertext stories form an graph model based on documents connected together by links.
The space of hypertext is too deep, rich and interesting to properly cover in this format, but I do want to briefly mention the significance of Twine and related tools in this context. To me, they appear to embody a strange kind of dualism when it comes to graphs, both embracing them visually, but also avoiding their direct representation from a programming and authoring perspective.
So I describe Twine as an implicit graph model because the graph structure is a product of constructing the story, not an explicit network that’s manipulated as the story representation when the story is being communicated to a reader. Instead, from an authoring perspective, Twine works more like a web design tool, focusing on adding markup and behavior to discrete passages of text.
It’s worth exploring Twine’s features and constraints in more detail in order to examine how the juxtaposition of an implicit visual graph model on top of what is essentially a wiki influences the style and presentation of fiction that Twine is widely used to create.
Narrative Graph Models
There are two core patterns for modeling explicit narrative graphs that I’ve identified so far. These patterns can be implemented in any property graph database or in-memory data structure that supports key/value properties on nodes and edges.
- Choices as Edges
- Choices as Nodes
Both provide a simple means of traversing a path through the story based on the choices made by the reader.
Choices as Edges
The most intuitive—perhaps naive—approach to modeling an interactive story is to treat the main scenes or passages of text in the story as nodes and the choices branching out to new parts of the story as edges.
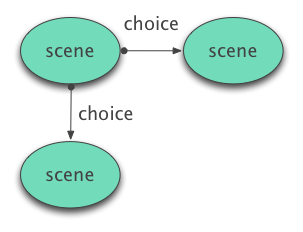
Information about the choice can be stored as properties on the edge. For instance, the choice will probably have a text paragraph or caption associated with it—the digital narrative equivalent of “To open the door, turn to page 70”.
This pattern is easy to understand and the structure is easy to build. The tradeoff for this simplicity is that some of the read queries end up being more complicated than they should be. Not all graph APIs have the same affordances for matching edges that they do for matching nodes. Having a unique ID for each edge is a requirement for doing simple lookups based on the choices made, although there are ways of working around this using node IDs and lists.
Another tradeoff is that supporting multiple choices linking to the same target scene is a bit more difficult with this approach. Not all choice-based narratives require this, but many do. It’s a particular feature of the Branch & Bottleneck narrative pattern, where the properties affected by choices accumulate and build up until closer to the end of the story, where they can be applied to great effect as the narrative branches rejoin.
In terms of UI, this structure encourages stories to separate the presentation of text from the presentation of choices to navigate through the story. For stories where the choices are embedded as links within the text itself, a markup language or hypertext model makes more sense.
Choices as Nodes
A more flexible and fine-grained approach involves giving each choice an explicit identity as a node in the graph. This is a specific instance of the more general graph modeling technique of turning things that seem like relationships into entities.
It requires the capability to treat the nodes in the graph as heterogenous rather than of a single type. This heterogenous treatment of data types might seem counter-intuitive at first, but it’s actually one of the exciting and powerful properties of graph databases which this technique takes full advantage of.
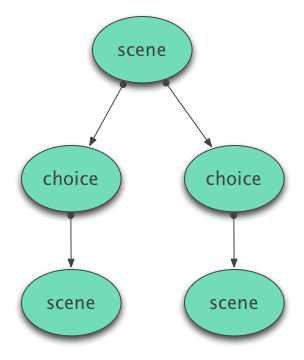
One way to think about it is that choices are surfaced as pieces of content in their own right rather than just being links between other primary pieces of content. This pattern would be extremely helpful when the narrative needs to support choices branching off in multiple directions without being directly prefigured by the text leading up to them.
This pattern might also be useful for bridging API constraints where the underlying graph technology doesn’t support unique IDs on edges or being able to easily do lookups and path traversals based on edge IDs.
The downside here of course is that because the graph structure is more complex, the path traversals are also going to be more complex, even if they may be straightforward to express in some graph query languages.
A feature of this pattern is the ability to represent an entire journey through a story as an ordered list of choice IDs.
Paragraphs as Nodes
This isn’t something I’ve tried yet. It’s potentially a bit more difficult to manage in a graph model, but might be well suited to a more interactive style of short text narrative (like the ‘Storylets’ used in FailBetter games). I’d like to explore this further.
In contrast, it’s worth pointing to tools like Ink which achieve effective results using an internal stack machine to manage the story state. An imperative programming model is a well-trodden path for working with interactivity at the phrase and sentence level.
People sometimes try to do similar things in Twine, but it’s frustratingly complex and repetitive as Twine is better suited to hypertext.
Character Supernodes
Graph databases are wholly different to traditional relational databases in the way that they expose all their different types of data as a single connected network (rather than slicing it up into isolated tables for each type). This connected structure leads to some interesting possibilities for directly integrating narrative text with metadata about the narrative.
In many cases, we will want to enhance our narrative data with information about viewpoint characters or lists of people and places mentioned in a scene. A straightforward approach would be to represent this metadata as key/value pairs stored in a separate lookup table or as properties on the nodes in the story.
Adding these properties to every node leads to a lot of duplication and changes become more and more difficult to manage as the story grows.
A logical next step would be to extract important metadata properties into first-class nodes in the graph, with each property reified as a specifically defined type or label. Extracting viewpoint characters as nodes like this leads to the Character Supernode pattern.
In graph theory, supernodes (also known as dense nodes) are nodes with a disproportionately high number of edges linking in and out of them. Real-world examples of supernodes are be Twitter accounts like Rihanna or Bieber, which have millions of followers in contrast to the average account which has only a handful. Our humble interactive narratives are extremely unlikely to reach the scale and complexity of large scale social networks, but it’s a useful shorthand for thinking about their connectivity.
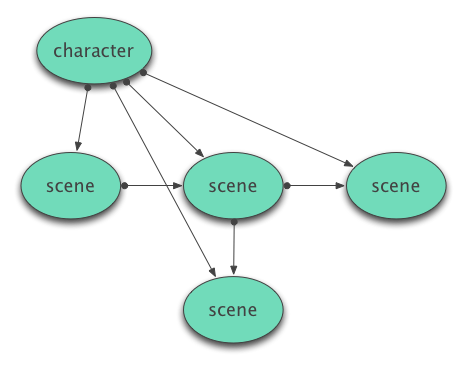
Character supernodes link to all elements of the story involving that character.
This pattern can be used to enable readers to switch between viewpoints or keep track of choices associated with multiple characters. It can also be used to break up the structure of a linear narrative by integrating multiple types of texts and documents associated with a character—emails, text messages, or life events can be modeled directly alongside a standard linear narrative. With these connections, it becomes straightforward to index an entire story by character (see for example, Arcadia by Ian Pears which maps out each character’s journey as a separate visual thread).
Next Steps
My intention is to continue updating these notes over time as I understand more about the specific implementation patterns for narrative graphs and start to explore more of these possibilities in practice.
One thing I’d really like to do is set up a short choice fiction story that can be used as a starting point for the examples on this page in order to illustrate the tradeoffs between the different graph models. Right now, these notes are getting a bit abstract, and would definitely benefit from far more concrete examples and links to demos.