Code is Not Inevitable
Crap Code is Inevitable raises a discomforting conclusion for experienced software developers who have felt the real pain that maladjusted code causes.
We finally accepted that requirements change, and so we invented Agile.
We must finally accept that code will be crap and so we must ???
Partly, the problem of crap code is one of experience, but experience is not necessarily the best arbiter of distinction. I have seen people with less than 2 years experience writing more cohesive and cleaner code than people with 5+ years experience. For some people, experience can actually be damaging, since it leads to bad habits forming and perpetuating from project to project.
The distinction between good code and crap code is essentially literary. Good code emerges from an intuitive ability to separate structure from intention – to compose minimalist flows of well formed cues that balance direct statements of logic with modular flexibility. Holistic, pattern based thinking is important, treating the locality of a single statement in the context of its position in a larger system, and also understanding that this position is fluid, and may change as the system changes and grows.
In many situations, I have been tasked with clean-up jobs that required me to descend into the middle of large web applications to tidy up and fix the malformed legacy left by previous developers. Because of this, I have a fair knowledge of the quality gradient that spans messy code, bad code, and code that can only be described as project-wrecking insanity. After going through this a few times, I started noticing a single quality shared by all the coders who were producing the most destructive output: they seemed to have a compulsive fear of changing code after it was written. The most visible symptom of this cognitive deficiency is the irrational avoidance of deletion, preferring instead to leave scattered lines of redundant code commented out, perhaps because of a thought that they ‘might need it later’. All kinds of weirdness gets left behind in commented out code, and none of it gives off a positive impression of those responsible. I learned that any time I saw this symptom spread through a project, I would have to deal with the worst excesses of architectural horror and cognitive debility.
I have come to believe that the vocabulary of technology is not sufficient to understand situations like these. Primarily, spaghetti code is a literary failing. Through my observations of the developers responsible for these wrecks — they often turned out to be poor prose writers and some were very arrogant about their coding abilities. I believe the core skill that these cowboys lack is that of editing – an instinctive drive towards pruning and tweaking that all good writers know is one of the most important components of literary creation.
Good programming can be taught, but it is incredibly difficult to master. It seems that an understanding of the pain caused by bad programming is necessary to effectively grasp why certain techniques are important. If crap code is inevitable, it may well be because code is text, and the skills needed to cultivate, shape, and edit text are not well understood by a vast number of people who become programmers. Indeed, one of the main difficulties of programming is learning how to balance the visual, structural, process oriented thinking required to design software with the written peculiarities of a programming language. In other words, how to balance what you know in your head about how the software should work with the need to create this architecture out of a constrained text syntax.
My response to the inevitability of crap code is that perhaps we ought to reconsider the idea that software be built from code at all.
If average developers struggle so much with the text based qualities of code, and we accept that the cathedral of ‘high literature’ has been demolished by a combination of Google searches and cut & paste splurges, then perhaps we should question whether the entire concept of programming in text syntax is sufficient for the future of software development?
There are, of course, alternatives to text syntax.
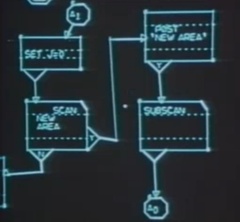
RAND Corporation’s GRAIL flow-chart language from 1968 was an early experiment to design a purely visual programming environment.
Visual programming is not a new idea, but it has never gained significant traction. One reason for this is that there is often a collective fear towards any disruptive idea that threatens the hegemony of dominant language paradigms, and this idea certainly upsets the huge investment in tools and technology that surrounds the entire software industry. But the most significant reason for this lack of traction is that past attempts to build non-text based paradigms of programming have failed. Badly.
In contrast, text based languages have proven their utility and longevity since the earliest days of programming. Some would even argue that Lisp – one of the oldest computer languages – is the apotheosis of all programming, and is still yet to reach the beauty and terror of its full potential. While I do feel a certain degree of sympathy for that view, we should not think that programming languages are the sole necessary form of interaction with computation. It is largely a historical accident that software is even built from text at all.
One of the most frequently cited failures related to visual programming, and a persistent theme of discussions is the CASE tools craze of the 1980’s. Despite some noteworthy innovations, CASE (as in Computer-Aided Software Engineering) is almost universally treated with derision and contempt, perhaps in part because it emerged during a major boom in personal computing and software marketing and the reality never lived up to the hype. The flexibility and universality of text syntax has always been more effective than any alternative, and this has remained the case despite the frequent regurgitation of CASE tool concepts in newer approaches like Model-driven architecture. In recent years, UML has also been frequently linked to these concepts, and countless products and open-source projects have tried to merge UML with code generation or executable bytecode with varying levels of success (see for example, Dirk Riehle, et al. on The Architecture of a UML Virtual Machine).
With few clearly articulated alternatives to MDA and UML, perhaps such overemphasis on models and diagrams has served to reinforce a status-quo contempt for non-text based programming, leading many programmers – even the smartest amongst them – to overlook a huge opportunity to evolve the discipline. The time has surely come to seriously question whether the future of software will continue to be forged in text based languages and move visual programming beyond the exclusive domain of PhD theses.
What we first need to realize is that visual programming has advanced a long way since the heyday of the CASE tools, and important innovations are beginning to spread from the fringes of research into wider communities of practice.
There are better ways to represent programs than text strings
Jonathan Edwards
Jonathan Edwards work on Subtext maps conditional logic into a simple format, introducing schematic tables for representing logic and control flow. Schematic tables eliminate the syntactic noise of imperative coding by projecting program logic into two dimensions – doing and deciding axes. What is the difference between a switch and an if-else statement? Logically, there is no difference, and the schematic tables reflect this, resulting in a notation that intuitively feels much closer to the concepts of boolean logic. Subtext has informed the design of a new language called Coherence which has a very interesting philosophy regarding the textual content of programs:
The keyboard is a very efficient input device, so having a way to type in syntax is effective. Likewise we have highly developed mental skills for reading and understanding grammatical text. I am using text as a UI mechanism, not as a representation. The internal representation is still in terms of semantic data structures as in Subtext, and more specifically, as first-class differences between structures. Text is ephemeral, not the source.
Alarming Development
At the enterprise end of the spectrum, Intentional Software is promoting a new system which promises to enable professionals to edit and manipulate software using their preferred domain language, rather than a specific programming language. Projectional editing enables source models to be translated to and from executable code, unlocking software from the tyranny of implementation languages being the only possible way to edit and change a system. JetBrains Meta Programming System is aiming in a similar direction and similarly, Microsoft are proponents of visual programming in the domain of robotics. Expect to see more of this.
Software code is an unsuitable way to express domain knowledge
Intentional Software
In fact, visual programming is far more ubiquitous than the mainstream software industry acknowledges. Most people familiar with audio synthesis will know about Max/MSP and Reaktor – both widespread and influential tools for building digital instruments from modular components. After the success of AgentSheets, the Scratch environment has exploded in popularity along with EToys, showing that visual languages are incredibly powerful ideas for teaching children about art and science.
The roots of visual programming can be traced back to a single application: Ivan Sutherland’s Sketchpad from 1963. In Doing with Images Makes Symbols (part 2), Alan Kay asserts that Sketchpad was also the first OOP environment, an incredible innovation considering the primitive hardware available at the time.
In his further discussion of computer literacy, Kay outlines three core aspects derived from an understanding of English literacy:
- Access literacy (reading)
- Creation literacy (writing)
- Genre literacy (shaping context of style and form)
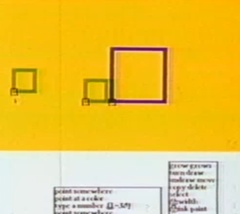
One of the first interactive drawing programs was built by a 12 year old girl participating in an education research group at PARC in 1975.
Much of the crap code referenced earlier results from cognitive models that are incompatible with these aspects of literature. In the case of cowboy developers, writing skills are expected to exist without the reading skills as a foundation. This is most apparent in the consistent behavior of incompetent programmers leaving behind scraps of commented out code and not deleting code that is redundant and does not contribute anything to the program. Nobody who actually read the code would do this. Learning how to read code would start developers on a pathway towards being able to create code that was itself readable but it’s a very difficult skill to encourage. This is a huge problem for the software and web design industry as the growth of the web makes it easier and easier for developers to cut & paste code with only partial understanding of how it works.
Perhaps in this choppy world of postmodern programming, partial literacy is just the expected result of the working conditions of modern software development. My belief is that it is unrealistic to assume better education or training will improve the situation – there are simply too many avenues for opportunistic jocks to learn coding through cut & paste slapdash. Rather than dismissing this as pure coding horror and continuing to preach to the converted, enlightened programmers might have more success by exploring alternative symbolic approaches to programming and studying how these approaches influence the process of learning. Explore approaches to programming that are effective in the context of internet downloading and cut & paste duplication, rather than clinging to our coveted text languages.
We are now at a stage in the evolution of computing where we can begin to manipulate software with higher level abstractions than what we are accustomed to using.
Software would no longer be a set of features in an application. Instead it would be millions and millions of simple transformations, which could be conveniently mixed and matched as needed.
The End of Coding as We Know It
If there is one inevitability, it is that more and more people will need the ability to program computers in the near future. As designers and programmers in the present, we need to stop thinking of these machines as being our own special domains of expertise and magic boxes to everyone else. Every person who uses a computer should be allowed to start with the potential of full write access – not just at the surface of software, but also being able to open up and make changes to the inside of the software. Software should be constructed in a modular and open way, that makes this possible.
Textual code will never die, but for the most part, it may well be replaced as the primary tool for building and manipulating software.