On Writing Machines
By Mark Rickerby
People don’t often use the term ‘writing machines’ to describe this topic, but I’ve found it to be a useful handle for bringing together a whole lot of the different techniques and philosophies I’ve been exploring over the past couple of years.
My definition of a writing machine is something mechanical—a tool, a toy, a set of rules, a program—that can be used to generate texts or narratives in their entirety without an author tapping on keys or manually dictating input. It doesn’t mean an author isn’t involved in the process, more that they are feeding inputs and parameters to a system and responding to feedback, rather than painstakingly etching out marks on a page.
1845: ‘The Eureka’

This process doesn’t necessarily have to involve code. The Eureka machine, a Victorian artefact that printed novelty verses, is possibly the first known computer for generating creative text, in this case turgid and dreary Latin poetry.
Sort of like a weird steampunk pokie machine, it could only display one line of text at a time, so readers had to rush to copy its output down on paper before it clanked over to the next step.
1953: ‘The Great Automatic Grammatizator’

Another early reference to this idea is Roald Dahl’s acerbic short story about a colossal machine programmed with all the rules of English grammar that slowly but surely destroys the entire global market for literature by dominating all the bestseller lists and running working writers out of their jobs.
Although it might look like a prescient commentary on emerging themes of runaway artificial intelligence and automation, critics suggest that it’s more to do with frustrations Dahl had towards publishers at the time. And today, we’re more likely to think about this sort of centralised computing force in relation to Facebook and Google’s domination of media, rather than machines displacing the work of novelists and poets (more on that later).
1962: MIT, SAGA II
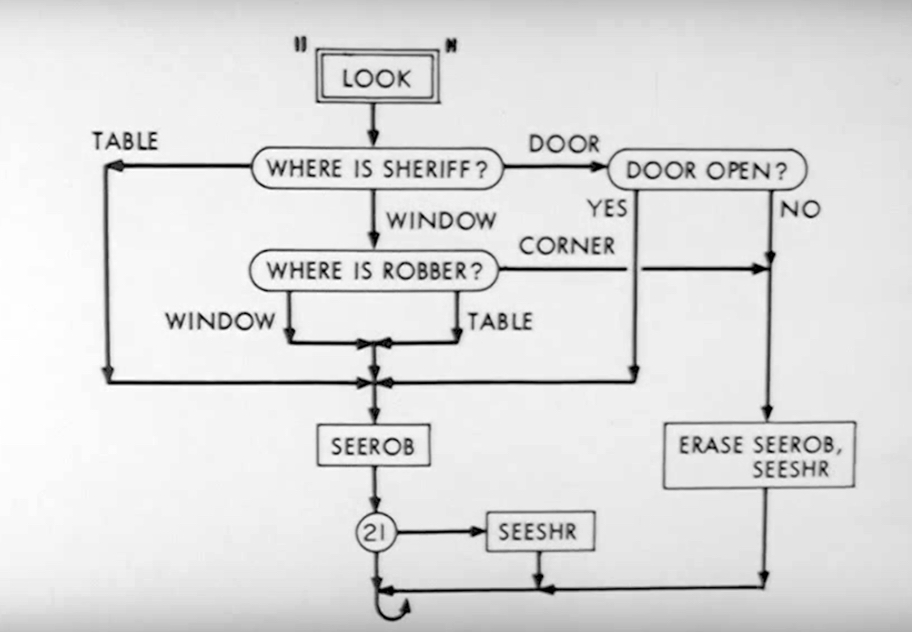
One of the most interesting early examples of a generative writing system is a cops and robbers script generator developed at MIT called SAGA II, which featured in a 1962 CBS television special.
The earliest known software system is a fairy tale generator by the linguist Joseph E. Grimes, which dates from around this same time.
By the mid 1970s, story generation was a relatively established research subject, closely connected to the symbolic AI paradigm that was ascendant in the MIT computing culture. Around the same time was the emergence of interactive fiction and tabletop storytelling games, which are closely related.
What properties should we look for in writing machines?
What do writing machines need to do? What properties should they support in order for their output to be recognisable to us as writing?
At a very high level, we can think of the function of writing machines as a combination of novelty and constraints. We expect the output to surprise us by being different each time, but we also want it to have a recognisable form and shape through familiar repeating patterns.
We want texts to be:
Well-formed in that they are syntactically and grammatically correct.
Comprehensible in a way that makes sense and is readable and coherent.
Meaningful through conveying ideas, saying something worth saying.
Expressive using elements like tone, mood and theme stylistically to reinforce meaning and convey emotion.
Apps, games and bots have additional needs:
Context-aware with access to facts about the state of the world.
Responsive to inputs by continuously running and reacting to change.
Do we even need to solve these problems?
Meeting the criteria for a generalised writing machine is extremely difficult, and nobody has cracked it a reusable way yet, so it’s worth considering if we can avoid doing any of this work and how that might impact our results.
For example, if we’re generating poetry, we might not need to care about meaningfulness—or even making sense and being syntactically correct.
If we’re generating automated reports and summaries of facts, we might not care about expressiveness.

I want to propose another way of thinking about writing machines, that avoids the difficulty of trying to solve all aspects of coherent language generation at once.
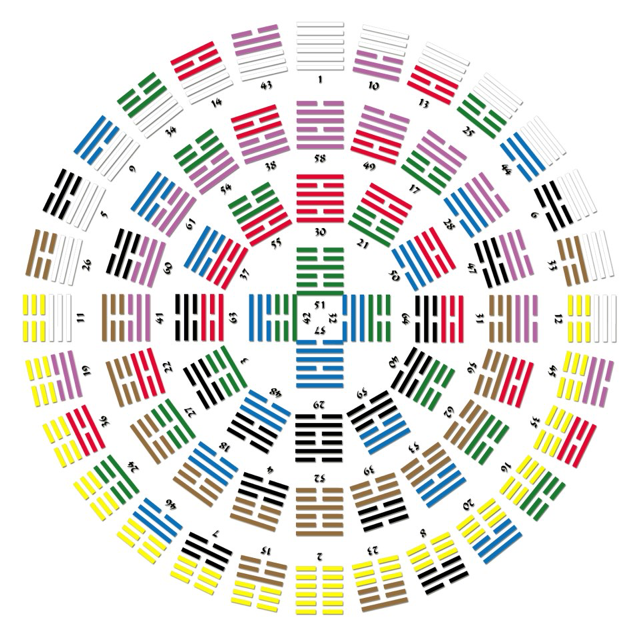
Building writing machines allows us to reconnect with much older traditions of novelty and constraint. Chinese hexagrams, European tarot cards and similar practices throughout history are in many ways the forerunners of generative writing and computational creativity.
Rather than reify and aestheticise these cultural practices, I want to reframe their function in a more profane context. Many of us tend to relate to them as mystical sources of artistic or creative inspiration but these fortune telling devices were once a meaningful and mundane part of daily life. They may have served a similar cultural function as many of our apps, casual games and trackers do today—our Fitbits, bullet journals, Candy Crushes, Instagram hashtags and weather forecasts, and I see huge potential for writing machines and other generative methods in this space.
Although I introduced this topic by outlining some sweeping and epic computational creativity challenges, I want to reinforce that there aren’t barriers to entry because of this formal difficulty. Many of these methods and ideas can be used effectively on a small scale, and this is where I want to start.
Strings & syntax
Let’s talk about agreement. By agreement, I mean countable nouns. This is a useful lens to look at some of the basic problems that emerge when generating small fragments of standalone text.
Imagine an app somewhere that wants to display the number of posts selected when the user taps on a list.
A naive string interpolation with the number of items leads to a grammatical quirk. It turns out that English nouns come in countable and uncountable varieties. When we splat out a string representing different quantities, we have to take this into account.
0 posts selected
1 posts selected
2 posts selected
Here’s a solution that doesn’t involve any extra logic or data awareness:
0 post(s) selected
1 post(s) selected
2 post(s) selected
As programmers, we’ve probably all done this at some point, but it’s lazy and crap. By avoiding proper language, we’re privileging our own convenience over the user experience, which isn’t a great way to develop things. It’s more difficult to read and it draws attention to the seam between the data and our design.
The usual way around this is to check the number of items in the list we’re displaying and show the different noun form, depending on whether the count is zero, one or more.
0 posts selected
1 post selected
2 posts selected
It’s now grammatically correct so the problem is solved, right?
Well, we now have a new problem, which is that we’ve started hard-coding grammatical rules into our app using list counts and if/else statements. If we need to generate further variations of text for different nouns, this is going to turn into unmanageable spaghetti really fast.
If you do a lot of web development, you probably already know how you’d go about solving this. For those of you using popular web frameworks and package managers, the solution comes for free by downloading a library that automatically handles inflections.
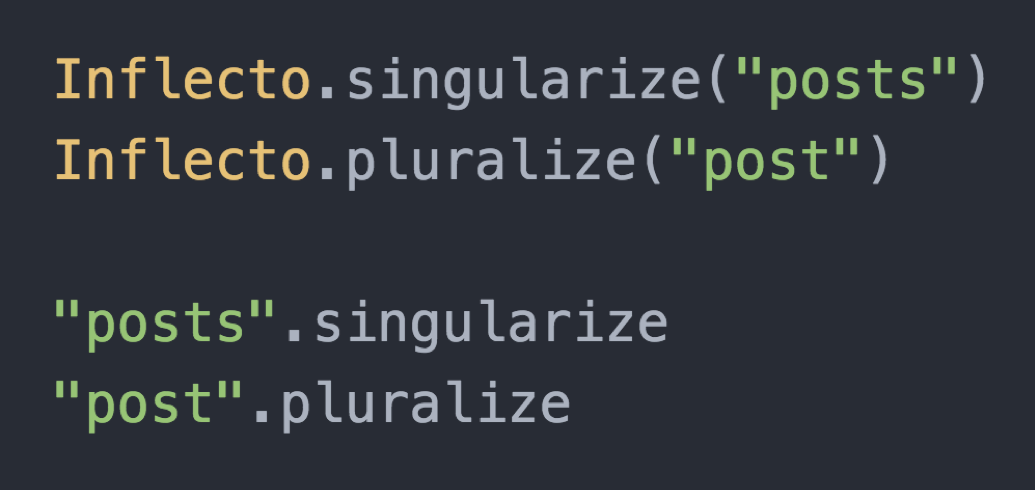
This is roughly what the code to do it looks like. Once you’ve wired the library into your app, you can transform nouns with correct plural inflection wherever you need to.
Is this a writing machine? We’re not really accustomed to thinking about basic string substitutions this way, but I think so, yes. It helps us meet the criteria of automated text being well-formed.
Let’s look at a related problem with nouns. What’s wrong here?
Eat a apple
Eat a banana
Eat a orange
We can’t eat a apple or a orange. Due to phonetic patterns etched into English grammar over centuries, we need to cut those vowels with a consonant, hence the naive generated text not sounding right.
Eat a(n) apple
Eat a(n) banana
Eat a(n) orange
This is just ridiculous.
Again, we can reach for a library that handles the language convention automatically, which will save a lot of frustration and awkwardness.

This gets the result we expect:
Eat an apple
Eat a banana
Eat an orange
So we can now compose these statements with nouns coming from dynamic data and have confidence that it will always display correctly.
We can get quite far with string substitution and pattern matching, but these techniques only help us with the tiny individual atoms of language.
How do we get from syntax to sense and meaning? If we want to generate larger and more comprehensive texts, we’re going to need more powerful methods.
Representations
To take things to the next level, we need to move beyond strings and look at different ways of representing writing that are closer to how we think about it in human terms.
There is no universal method of representing writing with computers beyond linear sequences of characters, so the way we structure our information about a text is an important force in shaping what we can do with that text.
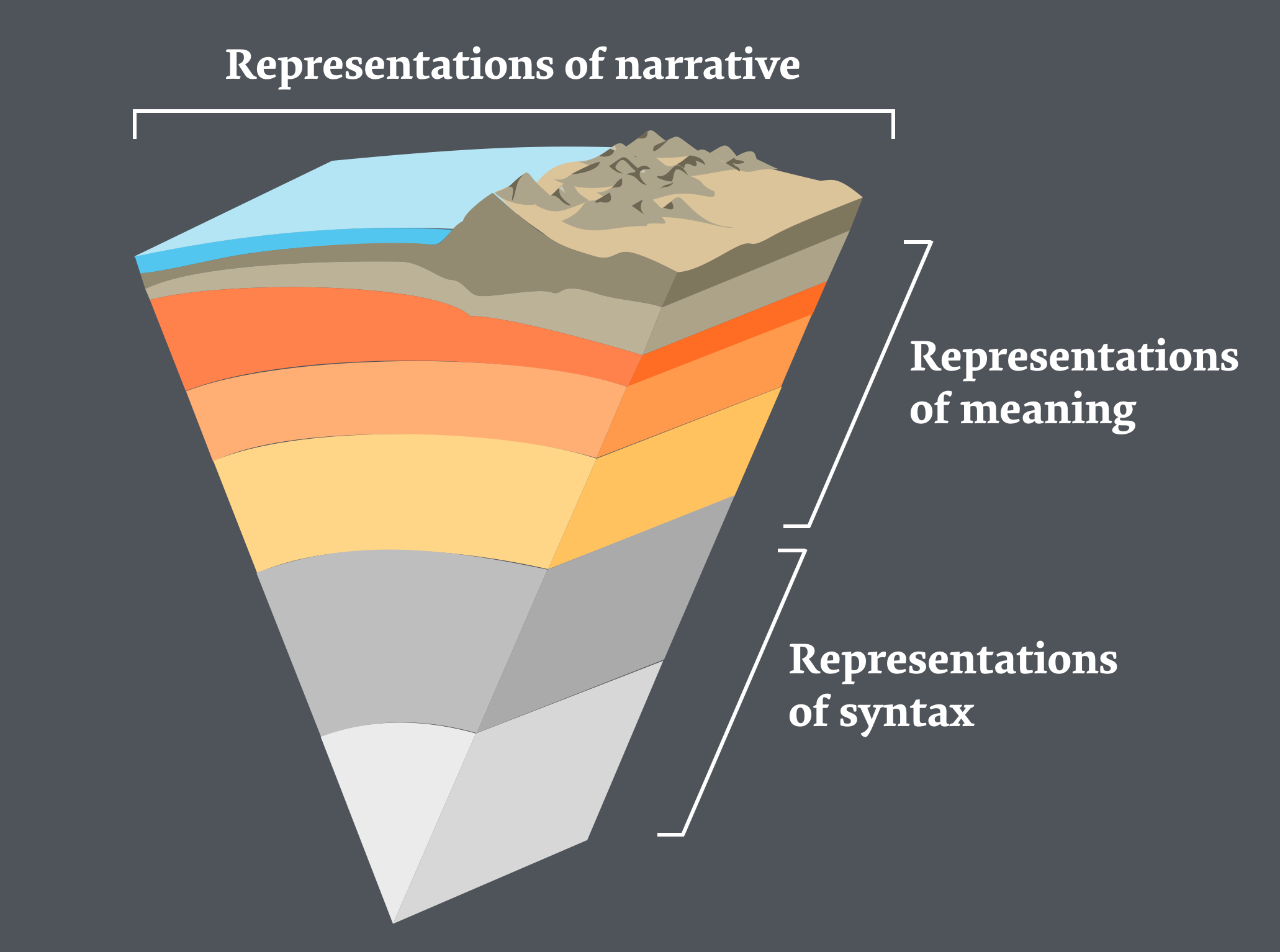
One way to think about this problem is to look at generated writing as a series of layers or rock strata, moving from the low level atoms of language in letters and words, up to the higher level of meaning in sentences and paragraphs, which supports the representation of narrative through elements of discourse, tone, characters, and plot structures.

In concrete terms, we can look at all these components of writing as a tree formed out of the different levels of structure found in a text.
This model is immensely helpful in tackling the complexity of text generation. It makes it easier to understand the different methods of working with generated text by thinking about what what level they apply to.
But another way of thinking about this model isn’t so much about the levels themselves, more about the direction we’re operating in—whether we’re ascending or descending through the levels. Depending on which path we take, we end up with very different levels of control over the resulting text.
We could be starting with structure—plots, narrative sequences, themes, tropes and all that—and figuring out how to turn that structure into text by working down towards sentences. Or we could be starting with a large corpus of existing texts, working from the smallest pieces of syntax with sense and meaning being emergent.
It turns out these aren’t just ways of classifying generative writing methods, but also AI philosophies that define the way we approach authorship.
Symbolic vs statistical approaches
The symbolic approach is about templates and top-down organisation, encoding our formalist ideas about the rules, patterns and constraints we want to apply to a piece of writing. It’s more intentionally directed, but also potentially complex and requiring a lot of manual effort to get right.
The statistical approach is to turn text into data that we can operate on mathematically, and process it using algorithms that aren’t always traditionally associated with natural language or text. Statistical methods usually avoid encoding rules about language or rules about narratives and plots. They treat text as a distribution of probabilities. It’s more akin to musical sampling and remixing than anything associated with traditional writing.
Symbolic |
Statistical |
|---|---|
‘Top-down’ |
‘Bottom-up’ |
Authored rules, world models |
Sampled from existing texts |
Examples: grammars, graph rewriting, agent-based systems, goal-directed planning |
Examples: n-grams, Markov chains, word vectors, recurrent neural networks |
My own research and methods are primarily focused on the symbolic approach, but before we go into that, let’s dive into generating text using the statistical approach, which is an infinite source of fun and amusement when you have interesting sources to draw from.
Markov chains
This is probably the most widely known and commonly used statistical method for randomly generating text.
Markov chains are models where the probability of the next event occurring depends on the preceding event. Lets say we have a bunch of sentences from a sample text. If we break these up into individual words, we can then work out the probability of possible next words that follow from the previous word.
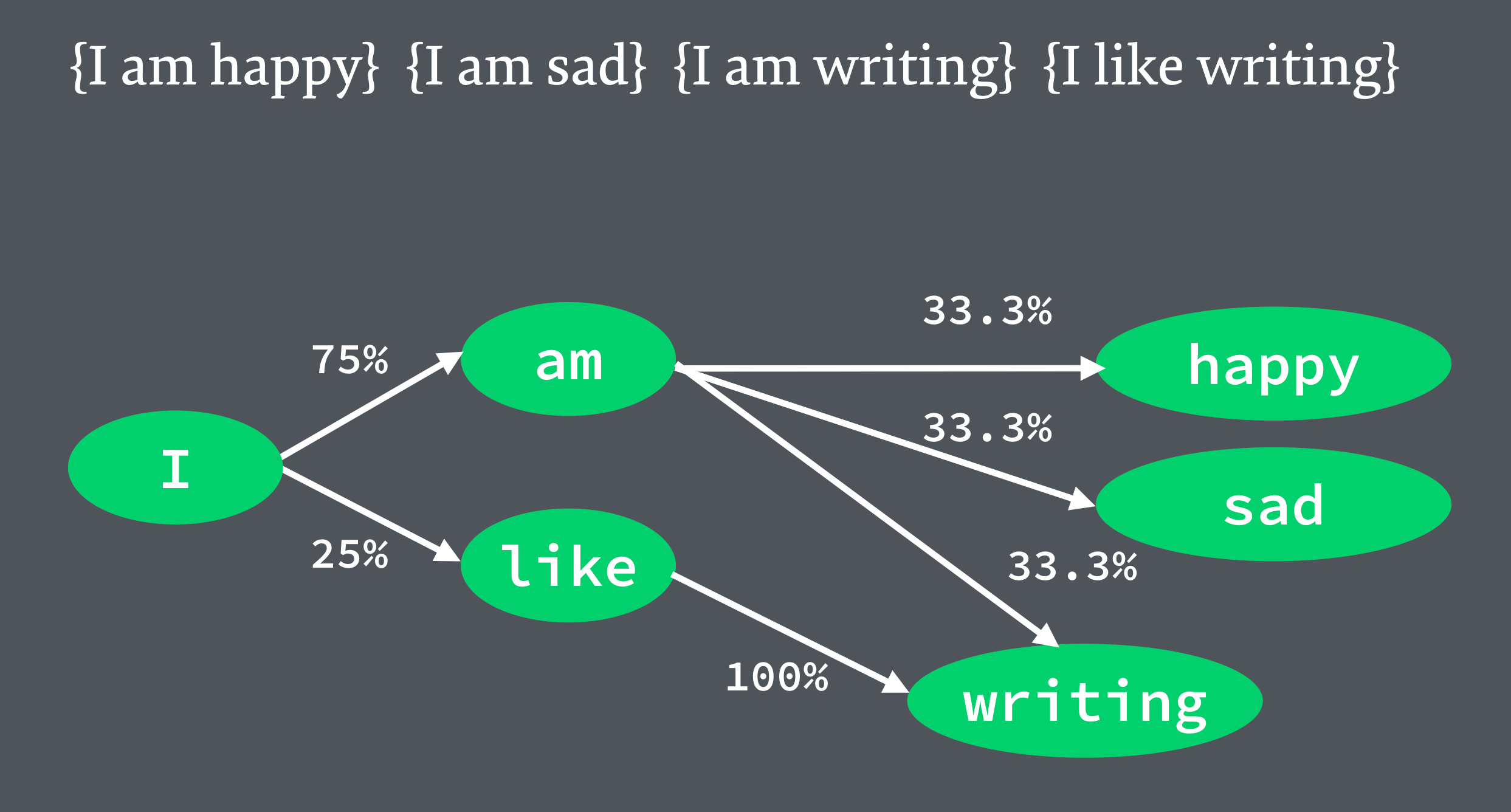
To generate text, we pick a starting word and move through the chain, randomly sampling the next word from the set of possible words.
When Markov chains aren’t carefully constrained, they can turn into a real mess and this is kind of what they’re famous for—the spam emails, the blathering nonsense of placeholder copy and SEO keyword scamming. Conversely, when used thoughtfully, they can be used to shape wildly creative juxtaposed texts with incredible depth, like the generated histories and stories within stories in Caves of Qud.
Here’s a sample of this style of writing that I created through blending a corpus of stories by Phillip K. Dick and Katherine Mansfield:
And good little Rags was very vague. Bother that old self again, “I began studying a Mind System when I did not say a word.”
At that she grudged having to cook it for me, haggard and wild and on the front porch and rang the bell. Here, half a mind to run after her; but then it is a state of acute distress.
She arched her plump small fingers, and pursed up his hand. It was like a rare, rare fiddle? A slender pale craft was moving along behind the pale dress of mine.
We're damn lucky they let us call it.
But Markov chains don’t have to operate on words. Here’s another little sample I threw together based on splitting a corpus of Māori words into 2 character long chunks of text (known as bigrams).
The result is meaningless, but retains the underlying feel of the language from a lexical standpoint.
oputeraka
waiwakohikiaoa
winenaiotou
koroko
karitipokoa
You can see how this technique could be used to build fantasy name generators or create fascinating gibberish that retains the flavour of its source.
Why does this work? Why is such a simplistic model so effective?
The distributional hypothesis
The distributional hypothesis comes from computational linguistics. It’s usually stated as: “Linguistic items with similar distributions have similar meanings”.
So, words appearing in similar contexts tend to refer to similar things.
It follows that if we analyse a large enough volume of text, we can create a set of mappings between words that reflects their web of relationships in common usage, without having to understand or derive the complex and arbitrary rules of the language.
Word vectors
When these statistical mappings between words are translated into multidimensional vector spaces, the associations between words can be manipulated using standard algebra for calculating distances and offsets.
A lot of the early research in this area looks at answering analytical questions like ‘which animal is most similar to a capybara?’ or ‘man is to woman like king is to?’.
Recently, poet and researcher Allison Parish has gone a step beyond analysis and shown how these representations can also be used for manipulating and generating text. With word embeddings represented numerically as vectors, it’s possible to use traditional signal processing techniques on text, leading to radical new possibilities for writing using functions like cross-fades, blurs and compression.
Learning machines
The various spinoff technologies and subdisciplines of machine learning are having a huge impact on computing today, but much of the research emphasises analytical decisions or predictions rather than meaningful and expressive creative output.
Amongst people working on generative writing, neural networks have a reputation for being not much better than Markov chains, despite their considerably more complicated levels of processing and resource consumption. But this may just be because we don’t yet have the right tools and frameworks to work creatively with these data structures and algorithms.
Some of the most fascinating work in this space involves completely breaking down machine learning conventions and approaching the problem as an artist would.
Authorial responsibility
There’s a huge caveat to building writing machines using statistical methods and machine learning, which is the ease of directly encoding the values and structural biases of source texts into models, which shape outputs in ways that have the potential to cause harm.
The vast potential for generating creative works from large data sets has to be constrained by authorial responsibility. Creators cannot necessarily escape the impact of their work by explicitly relinquishing control.
There’s really no straightforward and systematic way around this, though recent ideas about removing stereotypes from word vectors is a good starting point. This risk is an inherent property of the statistical approach, starting with source texts and working bottom-up.
Generative grammars
While still at the strata of words and sentences, let’s move on to talking about symbolic methods and the top-down approach, starting with generative grammars. These methods generally involve more effort on the part of the author to construct representations and content variations, leading to carefully crafted and expressive results.
The simplest explanation of what a grammar is a series of rules for producing strings. Traditionally in computer science, grammars are used for parsing text rather than generating it, but there’s no reason why it can’t work the other way.
Grammars offer direct authorial control over the fragments that combine to produce an output text.
This approach has been around for a long time. For a while, people would often assume that it’s out of fashion or out of date and soon to be superseded by some clever machine learning technique, but it just never happens. More recently, quite the opposite has happened with the huge surge in popularity of Tracery opening up these tools to new audiences and communities.
To explain how generative grammars work if you aren’t familiar with them, here’s a language agnostic example that generates different breakfast foods.
breakfast ⇒ baking “with” spread
spread ⇒ “marmite” “vegemite” “jam”
baking ⇒ “croissant” “toast”
toast with marmite
croissant with jam
toast with vegemite
At the top are the grammar production rules which are a combination of named symbols and strings that combine.
At the bottom, we see the generated text results of substituting these symbols to produce strings.
If we want to extend this to have different kinds of jam, we can replace the existing string with a symbol and introduce a new production rule to generate flavours of jam.
breakfast ⇒ baking “with” spread
spread ⇒ “marmite” “vegemite” jam
baking ⇒ “croissant” “toast”
jam ⇒ “strawberry jam” “apricot jam”
croissant with strawberry jam
toast with apricot jam
Hopefully you can immediately see how powerful and flexible this is. Grammars can be used to generate pretty much any kind of text. They give you amazing control over the output, but the catch is that you have to actually write the fragments of text and assign names to the rules.
Now with a sense of what grammars can do, I want to share a few examples from projects that put these constructs into practice.
The tiny woodland bot is my weird attempt to create a more gentle and refreshing environment on Twitter, where things have been pretty hectic for the past couple of years.

It basically builds a little grid of emojis based on a selection of trees, foliage, flowers and critters. The random choices are weighted so that trees and plants are more likely to be chosen than the other variations, which creates the mix of patterns that gives the bot its distinct visual feel.
The following is a sample from a much larger project. It’s part of a 50,000 word generated novel I made in 2015, called ‘The Gamebook of Dungeon Tropes’, based on the classic gamebooks and pick-a-path adventures that I had as a kid in the 1980s.

This code fragment shows a grammar for generating a confrontation with a dragon who seems really obsessed with delivering lame insults.
Because we’re naming the symbols in grammars, we can encode a lot of important information about the text to produce direct representations of meaning in a way that machine learning and statistical methods can’t. Having access to such labels is really helpful for reusing and extending grammars incrementally. Building up a library of generic rules and helper functions helps reduce repetitive effort and makes it easier to work with grammars creatively.
This kind of symbolic abstraction also helps us move from the levels of paragraphs, passages and narrative structures to the levels of words and sentences.
Grammars can actually be used to generate high-level stories and narrative structures too, but working with strings as output isn’t really the ideal way to do this so we’d need to modify grammar tools to emit raw data structures and be prepared to maintain complex tangles of parsing and generating and re-parsing.
There’s a far better way to represent narrative elements, which we’ll look at next.
Narrative graphs
To manage meaning and narrative, we need a smarter data structure than strings that helps us model the flows and relationships between ideas when we’re dealing with things like characters, plot events, dramatic tension and facts about a world. The tools I use for this are inspired by graph computing.
I think of narrative graphs as a model for defining a narrative text as a network of nodes and relationships. Each node in the graph represents a discrete unit of the story (chapter, scene, passage, paragraph, etc).
Narrative sequences (consequences of actions, choices, or the passage of time) can be created by drawing edges between the different nodes in the story.
These are some narrative graphs from my gamebooks project that model encounters with traps and enemies in the story.
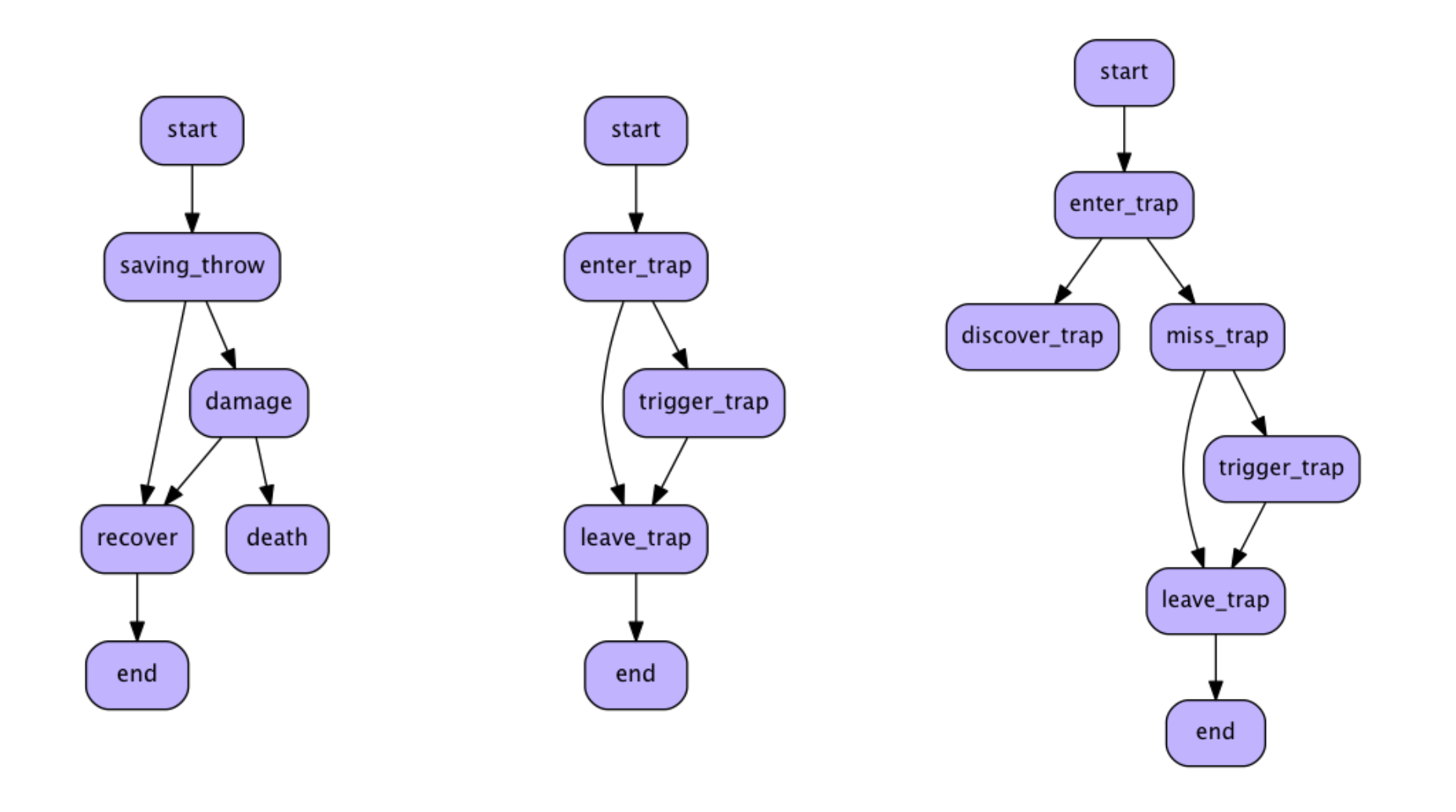
Each of these little graphs can be considered a story unto itself, but the real magic happens when you string lots of them together in interesting and intricate ways.
Constructing these graphs in code can be tedious, as you can see from this example which builds a flowchart of an encounter where the player might be hit and take damage.

The good news is we don’t have to do this each time. We can treat each little graph like a puzzle or template where we clone the basic shape over and over again and fill in the gaps with our own generated content.
Here’s another snapshot from a generated novel project. It’s a sequel to the dungeon gamebook, and takes the form of a journey through a vast world of planets and star systems. Each one of these nodes joins to a grammar which generates paragraphs and sentences for that particular part of the story.
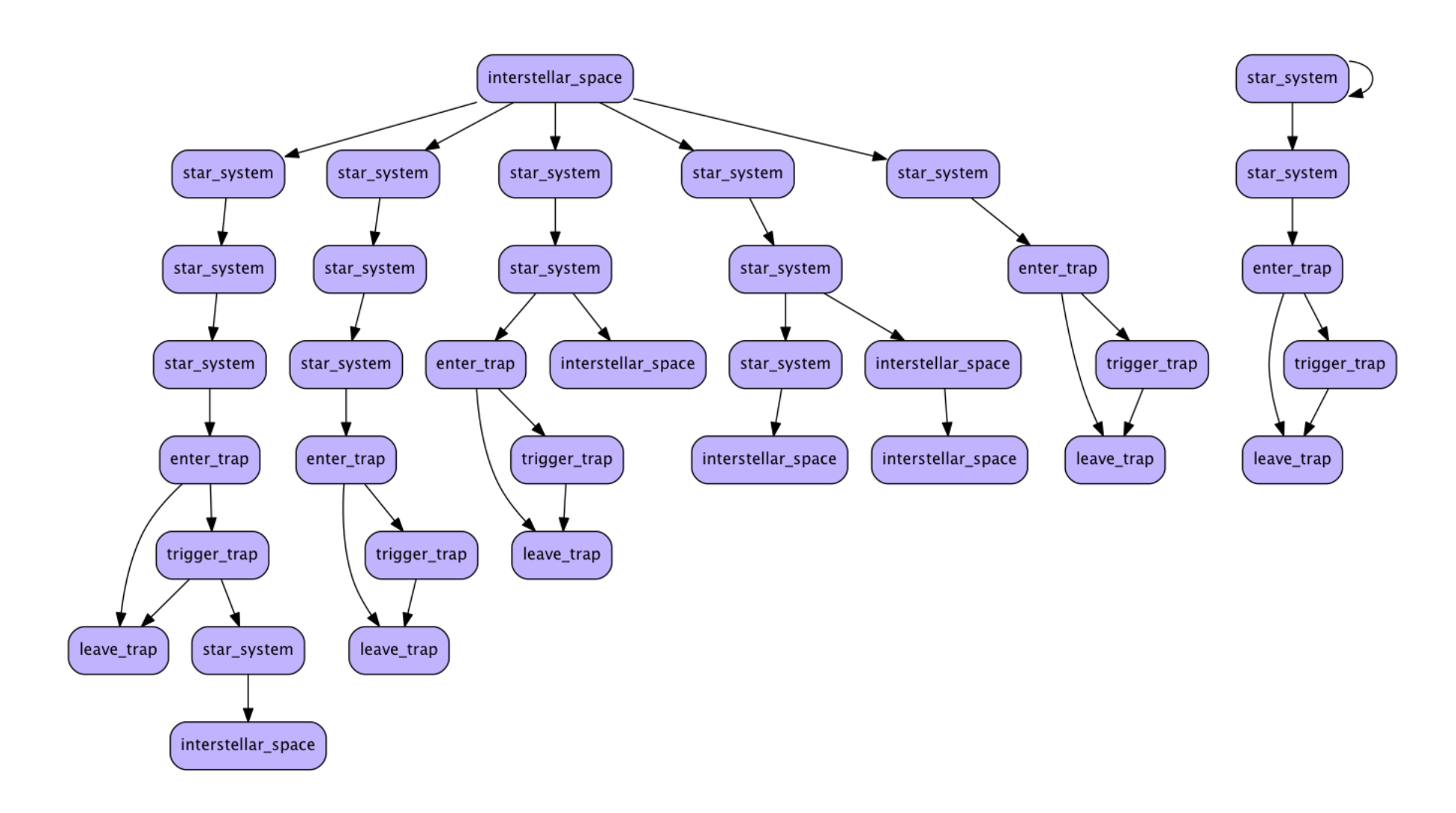
I’m building this based on rewriting and splicing chunks of narrative and events over and over to create the entire structure of choices and moments that can appear in the story.
One of the most powerful insights from graph computing is the idea of rewriting systems, also known as graph grammars.
The grammars we looked at earlier were based on string rewriting with the rule symbols producing either other rules or strings. This basic idea can also be applied to graphs—it’s possible to use the exact same left hand/right hand rule approach with graph topologies in place of symbols and substitutions. Graph grammars allow you to search a graph for all subgraphs of nodes and edges matching a particular pattern (left hand side rule), then replace those subgraphs with a new configuration of nodes and edges (right hand side).
This enables generators based on multi-pass processing steps where narrative structures at a high level of abstraction (eg: inciting incident ⇒ conflict ⇒ resolution) can be rewritten over and over with world details and specific plot and story elements.
Another possibility is generators based on the double diamond design process of diverge ⇒ converge.
World models and simulations
Graphs are an enormously powerful way to represent structure but they aren’t enough to support the most intricate and detailed writing machines.
Some of the most spectacular generative works have come from treating narrative as a separate frame or plan that can look into a complex world and navigate through it to tell a story.
You could think of this as inspired by the way that many authors build up complex backstories, character histories and maps for their projects. Though little of this material ends up embedded directly in the finished work, it helps authors inhabit the fictional world as they write and provides the foundation and detail to tell compelling and convincing stories.
Even on smaller projects, world models can be a powerful tool for organising and directing other techniques in use.
Here’s an example from the dungeon gamebook project again, where the world model was a simple random walk through a 2D space to create the spatial arrangement of connected passages.
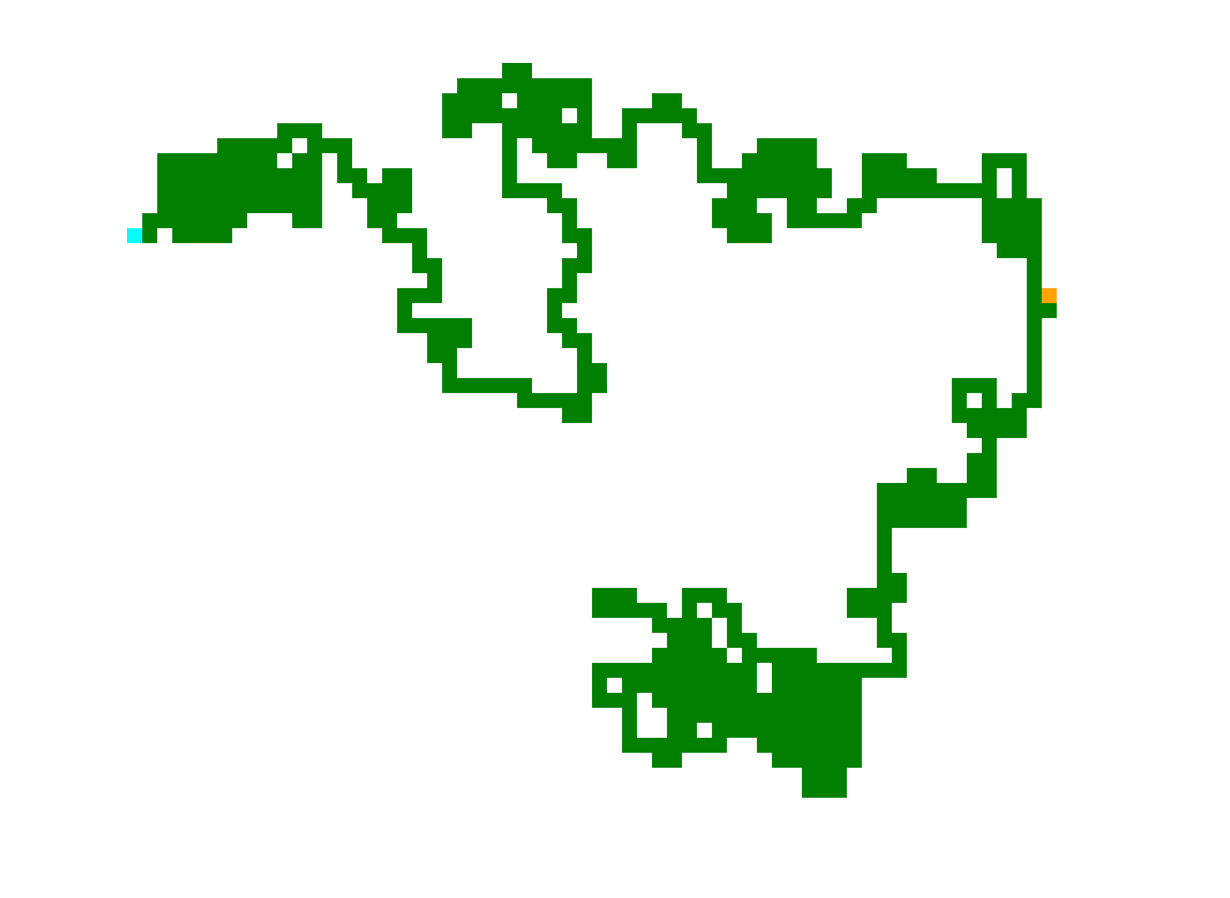
The world model underlying the starship gamebook is a vast almanac of randomly generated star systems and exoplanets.

These examples are relatively static. More dynamic methods involve agent-based simulations, where each character is represented as a separate agent that has individual motivations, goals and stats. Dramatic situations emerge as a result of interactions between the agents and changes to the world state that affect the agents.
The following example is dumped from an experiment I made to generate murder mystery stories. The characters are connected in a social network, with various enmities and motives setting up many potential murder scenarios. A combination of simulated interactions and Goal-Oriented Action Planning can be used to derive the events of an actual story from this web of possibilities.
Composition
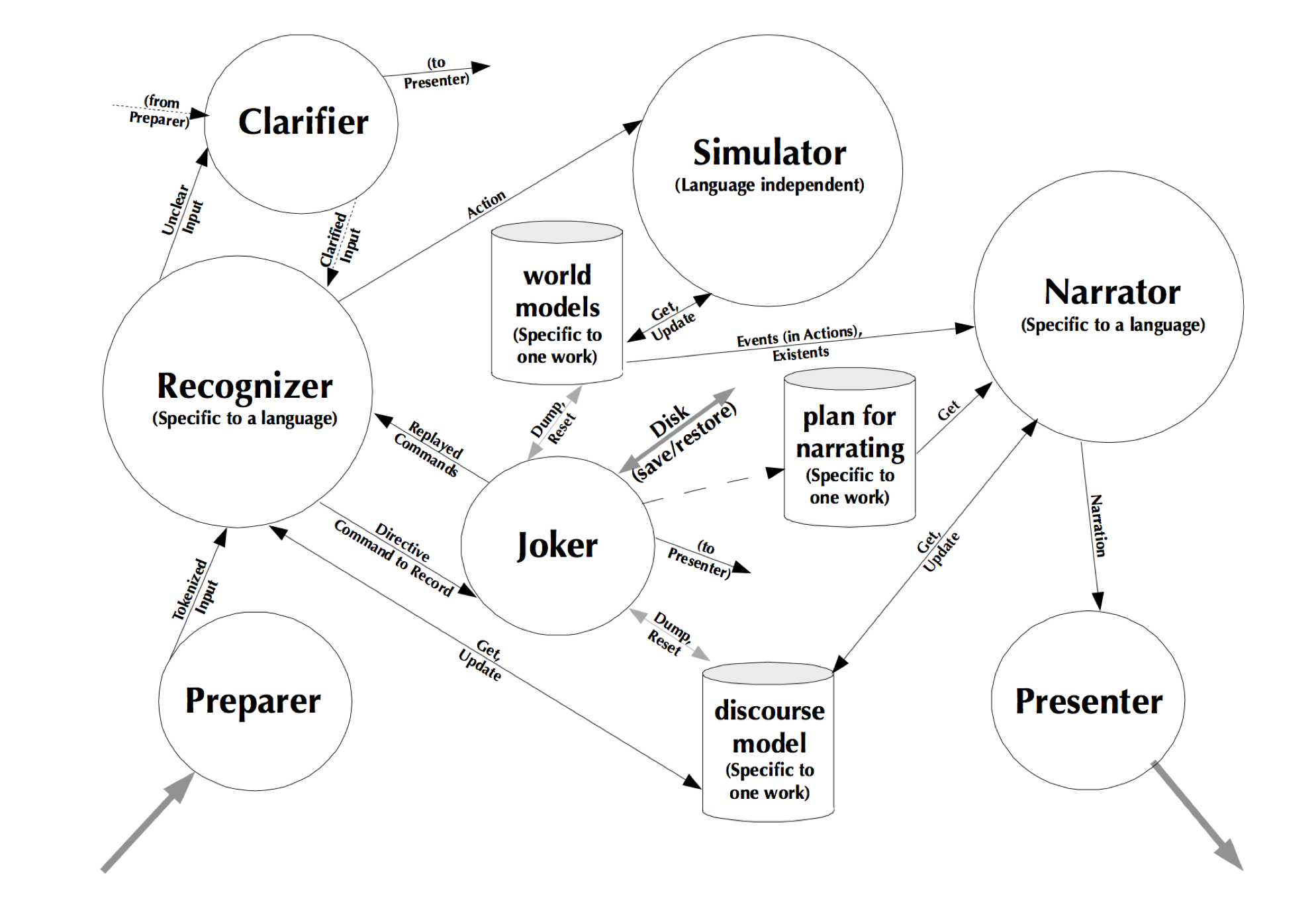
All of the methods we’ve explored here have different strengths and weaknesses, and operate at different levels of the writing process.
Statistical methods require meticulous corpus selection and pruning to get right, while symbolic methods require a big investment in modelling and design.
Any writing machine that comes close to meeting the criteria of well-formed, comprehensible, meaningful and expressive output will need to be composed of multiple generative methods, each addressing a specific level of language or narrative, with their inputs and outputs feeding one another.
“Generating Narrative Variation in Interactive Fiction”, Nick Montfort
Motivation & purpose
After going through all these methods and approaches for text generation, let’s wrap up by thinking a bit more about motivation and purpose. Why bother with writing machines? What’s the point of all this?
Creating large volumes of text that would be difficult to manage otherwise
One very obvious motivation is when we want to create large volumes of text that would be complicated, messy and time consuming to manage otherwise.
This is actually how I got started in this area. In 2014, I was working on a novel manuscript with a lot of loose material around the edges that led to the idea of exploring the story as an app. Through emails, documents and fake web pages, I could allow readers to inhabit the desktops and phone screens of each character and see the world through their eyes.
I realised I’d need a lot more content to make the fake desktop experience feel continuous and cohesive. This led me to wonder… What if I didn’t have to manually write it all? Could I generate expressive text automatically?
So, you’ve seen some of the resulting work that has come out of asking that question. It has kind of consumed my life.
This is largely an instrumental motivation which is fairly straightforward to explain, but there’s some potential awkwardness here. Although they have completely different—and I guess far less ethical—incentives, my motivation here is really the exact same motivation as a spammer.
Exploring weird forms of writing that were previously impossible
There are other reasons to build writing machines that are more about creativity and art.
Exploring new forms of writing is a huge inspiration for me. There’s not always a particular end goal here. It’s really more of a focus on the process and where that leads.
The best example I have of things that were once impossible, but now realisable is ‘The Library of Babel’ by Borges. It’s a brilliant short story from the mid-20th century which twists information theory into a sublime and deeply disturbing thought experiment.
Imagine a library the size of the universe, with uniform hexagonal chambers stacked with books, and those books contain every combination of every letter in every position. The librarians are obsessed with seeking order and pattern—they can assume that somewhere in the library is a book which tells the story of every detail of their lives, the complete works of Shakespeare, every bureaucratic document ever written. Every possible sequence that could fill a 410 page book is buried in there somewhere.

1941: Borges, ‘The Library of Babel’
A universe-size archive of all possible books of 410 pages with 26 letters.
This story has been blowing people’s minds for decades. What’s even more mind blowing is that modern computers have large enough address spaces to simulate the Library of Babel at its exact scale of information. And sure enough, this now exists online where you can put yourself into the original story, exploring book by book.
Something that was a source of existential terror in the mid 20th century is now a toy.
Not a motivation: Replace traditional authoring (and authors) with machines
A lot of stuff in the media about AI and machine learning and the future of jobs is extremely problematic. AI is so often personified as computers gaining agency and autonomy far beyond anything that has ever been proven or demonstrated.
When people argue that novelists, poets and artists will eventually be replaced by AI, they are massively overlooking how the design of these systems and the shape of their training data has been deliberately constructed by humans with intent at every step of the way. Making machines that can produce creative works with minimal human input will always be a feat of human purpose and ingenuity. Computing is inseperable from its social context.
So those of us working on creative uses of this technology should be thinking about practices that push back against the dehumanisation and lack of ethics that contemporary AI has unfortunately become known for.
When we think about designing and building generative systems, we should also be thinking about how we communicate working decisions and surface parameters in ways that are legible to artists and creators, rather than constructing more opaque black boxes.
It’s in our best interests as artists, designers and programmers with privileged access to these tools to reinforce and promote the idea that the purpose of computing is to support and enhance human creativity, not to destroy it.